ML-Ensemble¶
A Python library for memory efficient parallelized ensemble learning
NOTE: This site hosts documentation for version 0.1.6. Visit ml-ensemble.com for up-to-date documentation.
ML-Ensemble is a library for building Scikit-learn compatible ensemble estimator. By leveraging API elements from deep learning libraries like Keras for building ensembles, it is straightforward to build deep ensembles with complex interactions.
ML-Ensemble is open for contributions at all levels.If you would like to get involved, reach out to the project’s Github repository. We are currently in beta testing, so please report any bugs or issues by creating an issue. If you are interested in contributing to development, see Hacking ML-Ensemble for a quick introduction to ensemble implementation, or check out the issue tracker.
Core Features¶
Modular build of multi-layered ensembles¶
Ensembles are build as a feed-forward network, with a set of layers stacked on each other. Each layer is associated with a library of base learners, a mapping from preprocessing pipelines to subsets of base learners, and an estimation method. Layers are stacked sequentially with each layer taking the previous layer’s output as input. You can propagate features through layers, differentiate preprocessing between subsets of base learners, vary the estimation method between layers and much more to build ensembles of almost any shape and form.
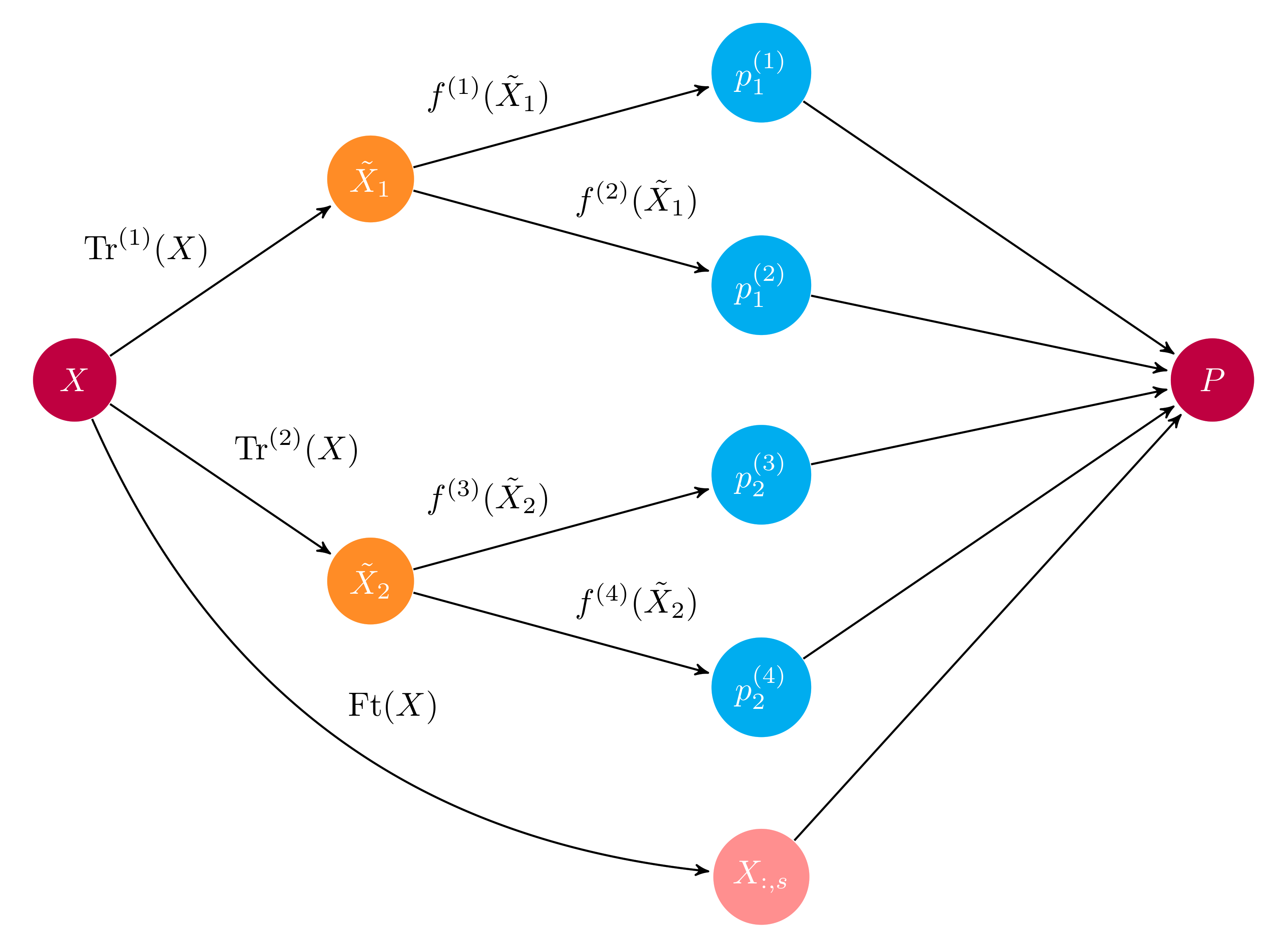
The computational graph of a layer. The input \(X\) is either the original data or the previous layer’s output; \(\textrm{Tr}^{(j)}\) represents preprocessing pipelines that transform the input to its associated base learners \(f^{(i)}\). The \(\textrm{Ft}\) operation propagates specified features \(s\) from input to output. Base learner predictions \(p^{(i)}_j\) are concatenated to propagated features \(X_{:, s}\) to form the output matrix \(P\).
Transparent Architecture API¶
Ensembles are built by adding layers to an instance object: layers in their
turn are comprised of a list of estimators. No matter how complex the
ensemble, to train it call the fit method:
ensemble = Subsemble()
# First layer
ensemble.add(list_of_estimators)
# Second layer
ensemble.add(list_of_estimators)
# Final meta estimator
ensemble.add_meta(estimator)
# Train ensemble
ensemble.fit(X, y)
Memory Efficient Parallelized Learning¶
Because base learners in an ensemble are independent of each other, ensembles benefit greatly from parallel processing. ML-Ensemble is designed to maximize parallelization at minimum memory footprint. By sharing memory, workers avoid transmitting and copying data between estimations. As such, ML-Ensemble typically require no more memory than sequential processing. For more details, see Memory consumption.
Expect 95-97% of training time to be spent fitting the base estimators. Training time depends primarily on the number of base learners in the ensemble, the number of threads or cores available, and the size of the dataset. Speaking of size, ensembles that partition the data during training scale more efficiently than their base learners.
Differentiated preprocessing pipelines¶
As mentioned, ML-Ensemble offers the possibility to specify for each layer a set of preprocessing pipelines to map to subsets (or all) of the layer’s base learners. For instance, for one set of estimators, min-max-scaling might be desired, while for a different set of estimators standardization could be preferred.
ensemble = SuperLearner()
preprocessing = {'pipeline-1': list_of_transformers_1,
'pipeline-2': list_of_transformers_2}
estimators = {'pipeline-1': list_of_estimators_1,
'pipeline-2': list_of_estimators_2}
ensemble.add(estimators, preprocessing)
Dedicated Diagnostics¶
To efficiently building complex ensembles, it is necessary to compare and contrast a variety of base learner set up. ML-Ensemble is equipped with a model selection suite that lets you compare several models across any number of preprocessing pipelines, all in one go. Ensemble transformers can be used to “preprocess” the input data according to how the initial layers of the ensemble would predict, to run cross-validated model selection on the ensemble output. Output is summarized for easy comparison of performance.
>>> DataFrame(evaluator.summary)
test_score_mean test_score_std train_score_mean train_score_std fit_time_mean fit_time_std params
class rf 0.955357 0.060950 0.972535 0.008303 0.024585 0.014300 {'max_depth': 5}
svc 0.961607 0.070818 0.972535 0.008303 0.000800 0.000233 {'C': 7.67070164682}
proba rf 0.980357 0.046873 0.992254 0.007007 0.022789 0.003296 {'max_depth': 3, 'max_features': 0.883535082341}
svc 0.974107 0.051901 0.969718 0.008060 0.000994 0.000367 {'C': 0.209602254061}